Daniel Ciocîrlan
14 min read •

Share on:
This article is for the Java/Scala programmer who wants to decide which framework to use for the streaming part of a massive application, or simply wants to know the fundamental differences between them, just in case.
I’m going to discuss the main strengths and weaknesses of Akka Streams, Kafka Streams and Spark Streaming, and I’m going to give you a feel of how you would use them in a very simple word-counting application, which is one of the basic things to start with when one learns any distributed programming tool.
I’m going to write Scala, but all the frameworks I’m going to describe also have Java APIs.
Kafka Streams is a client library for processing unbounded data. What does that mean? Client library means that the application we write uses the services provided by another infrastructure (this case a Kafka cluster). So we interact with a cluster to process a potentially endless stream of data. The data is represented as key-value records, which makes them easy to identify, and they are organized into topics, which are durable event logs, essentially persistent queues of data which is written to disk and replicated. In this architecture, we have producer applications pushing records into these topics - e.g. if you have an online store, you’d like to keep track of everything that happened to an order - and on the other hand we have multiple consumer applications which read the data in various ways and starting at various points in time in these topics.
This way of structuring the data allows for highly distributed and scalable architectures, which are also fault-tolerant. Kafka also embeds the exactly-once messaging semantics, which means that if you send a record to Kafka, you will be sure that it gets to the cluster and it’s written once with no duplicates. This is particularly important because this mechanism is extremely hard to obtain in distributed systems in general.
From the way Kafka is organized, the API allows a Java or Scala application to interact with a Kafka cluster independently of other applications that might be using it at the same time. So this independence of applications accessing the same distributed and scalable service naturally incentivizes the use of independent microservices in your big application.
object WordCountApplication extends App {
import Serdes._
val props: Properties = {
val p = new Properties()
p.put(StreamsConfig.APPLICATION_ID_CONFIG, "myFabulousWordCount")
p.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "my-kafka-broker-url:9092")
p
}
val builder: StreamsBuilder = new StreamsBuilder
val textLines: KStream[String, String] =
builder.stream[String, String]("TextLinesTopic")
val wordCounts: KTable[String, Long] = textLines
.flatMapValues(textLine => textLine.toLowerCase.split("\\W+"))
.groupBy((_, word) => word)
.count()(Materialized.as("word-counts-table"))
wordCounts.toStream.to("WordsWithCountsTopic")
val streams: KafkaStreams = new KafkaStreams(builder.build(), props)
streams.start()
sys.ShutdownHookThread {
streams.close(10, TimeUnit.SECONDS)
}
}
This is how a word count application would look like in Kafka Streams. Now this code is quite heavy to take all in at once, so I’ll break it down.
import Serdes._
Kafka stores records in binary for performance, which means it’s up to us to serialize and deserialize them. We can do this with this import of serializers and deserializers (Serdes) automatically in Scala.
val props: Properties = {
val p = new Properties()
p.put(StreamsConfig.APPLICATION_ID_CONFIG, "myFabulousWordCount")
p.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "my-kafka-broker-url:9092")
p
}
The first part of an application invariably needs to configure the details of the Kafka cluster it’s going to connect to. This will use a Java-style API, which I personally hate as a predominantly Scala programmer. Java folks might be much more comfortable with this.
val builder: StreamsBuilder = new StreamsBuilder
val textLines: KStream[String, String] =
builder.stream[String, String]("TextLinesTopic")
Next, we read the records as key-value pairs from the topic that we want, using a builder pattern.
val wordCounts: KTable[String, Long] = textLines
.flatMapValues(textLine => textLine.toLowerCase.split("\\W+"))
.groupBy((_, word) => word)
.count()(Materialized.as("word-counts-table"))
Then we will apply some functional programming operators on the stream, as if it were a collection, and we will turn that stream into a table. Kafka Streams has this notion of a table which allows for data aggregation and processing. Kafka has a stream-table duality which allows us to convert back and forth between them.
wordCounts.toStream.to("WordsWithCountsTopic")
Speaking of conversion, we might want to convert this table to a stream and feed it into another topic that some other application might be interested in reading from.
val streams: KafkaStreams = new KafkaStreams(builder.build(), props)
streams.start()
sys.ShutdownHookThread {
streams.close(10, TimeUnit.SECONDS)
}
And finally, we just need to start the streams and setup a graceful stop, because otherwise the streams are static and won’t do anything.
The major benefit of Kafka Streams is that a Kafka cluster will give you high speed, fault tolerance and high scalability. Kafka also provides this exactly-once message sending semantics, which is really hard in distributed systems as otherwise many other frameworks are unable to offer this kind of guarantee and as such you might end up with either duplicates or data loss. At the same time, Kafka incentivizes the use of microservices using the same message bus to communicate, and so you have the power and control to set up your own inter-microservice communication protocol via Kafka.
Of course, Kafka is not without its downsides. As a predominantly Scala programmer, I hate Kafka’s imperative Java-style API but I’ll swallow the pain for Kafka’s otherwise excellent capabilities. Another downside is that if you want to have Kafka in your architecture, you will need to set up a separate Kafka cluster that you will need to manage, even though you won’t necessarily need to allocate dedicated machines. Kafka is also highly configurable, but you need to know the configurations in advance to make it work at all. Finally, Kafka supports only the producer-consumer type architectures. You can also simulate other architectures, but it never feels as though it was meant to support it naturally - or, as some people like to say, “first-class” - so even though Kafka is excellent for this particular purpose, it’s not as versatile as other frameworks.
That said, let’s move onto Akka Streams. Akka Streams is an extremely high-performance library built for the JVM, written in Scala, and it’s the canonical implementation of the Reactive Streams specification. The tenets of the Reactive Manifesto are responsiveness, elasticity, fault-tolerance and message-driven semantics, all of which are at the core of Akka Streams. In here you have total control over processing individual records in what could be an infinite amount of data and 100% control over streaming topologies of any configuration. Akka Streams is powered by the very successful actor model of concurrency and streaming components are built off asynchronous individual components that can process the data in any way you want.
The major strengths of Akka Streams are again high scalability and fault tolerance, but in a different way, as we will see in the code. Akka Streams offers an extremely versatile and concise streaming API which evolved into its own Scala-based DSL, and you can simply “plug in” components and just start them. At the same time, Akka Streams also offers a low-level GraphStage API which gives you a high degree of control over the individual logic of particular components.
As I mentioned, Akka Streams is highly performant and fault-tolerant, but it was built for a different purpose. While in Kafka you used it as a message bus and your application was a client API for the Kafka cluster, in here Akka Streams is an integral part of your application’s logic. You can imagine Akka Streams like the circulatory system of your application, whereas Kafka is just an external well-organized blood reservoir.
val source1 = Source(List("Akka", "is", "awesome"))
val source2 = Source(List("learning", "Akka", "Streams"))
val sink = Sink.foreach[(String, Int)](println)
val graph = GraphDSL.create() { implicit builder =>
import GraphDSL.Implicits._
val wordCounter = Flow[String]
.fold[Map[String, Int]](Map()) { (map, record) =>
map + (record -> (map.getOrElse(record, 0) + 1))
}
.flatMapConcat(m => Source(m.toList))
val merge = builder.add(Merge[String](2))
val counter = builder.add(wordCounter)
source1 ~> merge ~> counter ~> sink
source2 ~> merge
ClosedShape
}
RunnableGraph.fromGraph(graph).run()
So let’s look at how we could build a word count application with Akka Streams. Even if you’re experienced with Scala, this code might still be too concise. This is one of the drawbacks of Akka Streams. From my experience and from my students’ experience, it’s generally pretty tough on beginners regardless of your previous experience. But fear not, I’ll break it down. Here are the main pieces of the code.
val source1 = Source(List("Akka", "is", "awesome"))
val source2 = Source(List("learning", "Akka", "Streams"))
val sink = Sink.foreach[(String, Int)](println)
The first 3 lines build the original sources, which will emit the elements (in our case strings) asynchronously.
val wordCounter = Flow[String]
.fold[Map[String, Int]](Map()) { (map, record) =>
map + (record -> (map.getOrElse(record, 0) + 1))
}
.flatMapConcat(m => Source(m.toList))
The interesting piece which actually computes the word count is here, where we do a fold like we would on a simple list of Strings. Looks very concise, hard to look at and it definitely needs some getting used to, but if you’ve worked with Scala collections a lot, this shouldn’t look too alien. I hope.
val merge = builder.add(Merge[String](2))
val counter = builder.add(wordCounter)
source1 ~> merge ~> counter ~> sink
source2 ~> merge
However, that’s not the interesting piece and the big strength of Akka Streams. The magic happens here, where we simply plug the different streaming components with their own logic.
The visual graph that resembles the stream looks like this.
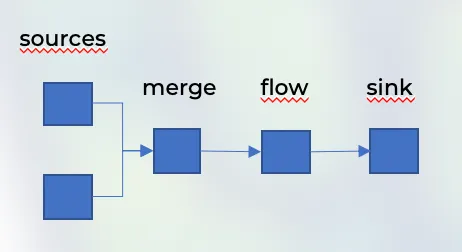
Now take a look at the code.
source1 ~> merge ~> counter ~> sink
source2 ~> merge
So notice we have a very similar representation of the streaming topology directly in the code! Some of you might go “meh”, but it’s hard to overstate how easy it is to construct arbitrary streaming layouts in just 3 lines of code, completely asynchronous, high speed and fault-tolerant.
So let me discuss the big ups and downs with Akka Streams.
Because Akka Streams is a Reactive Streams implementation, it naturally follows all the tenets of the Reactive Manifesto, which are elasticity, responsiveness, fault-tolerance and message-driven behavior. As such, it offers extreme speeds and high scalability. The API is extremely powerful and is the closest I’ve ever seen to a fully visual representation. At the same time, Akka Streams offers a low-level GraphStage API which gives you all the control in the world for custom streaming logic, for example to batch data or to manually interrupt or redirect a stream – really, the possibilities are endless. One of the best parts of Akka Streams is that it can seamlessly connect to Kafka with the Alpakka Kafka connector. Akka Streams was built as a development library for applications, and so you’re not programming as a client API, like you did with Kafka, but you’re using it as you would any other library for building a distributed application.
The downside of Akka Streams are that Akka Streams is very hard to learn and wrap your head around. I know people who were joking that the people at Lightbend made it so hard so that only they could understand it. At the same time, Akka Streams is like the C++ of streaming, you can easily shoot yourself in the foot even though you have all the power in the world (perhaps especially because you have all the power in the world). At the same time, although Akka (in all of its might) can scale really well if you use the entire suite with clustering & co, integrating Akka Streams for scalability will be a challenge in general. The fact that Akka Streams is an integral part of your application is both a blessing and a curse, because like any “building” library, you need to adopt a certain style of thinking.
Now let’s move on to Spark Streaming, which is a natural streaming extension of the massively popular Spark distributed computing engine. The purpose of Spark streaming is to process endless big data at scale. You have a choice between two API levels: one low-level high-control API with Discretized Streams (DStreams) and the other very familiar DataFrame API, which is also called Structured Streaming and offers an identical API to the regular “static” big data. Spark is naturally scalable and fault-tolerant from the get-go and functions in two output modes: micro-batch, in which at every interval Spark will add up all the data it gathered so far, and continuous mode which offers lower-latency (experimental at the moment of this writing).
The big strengths of Spark are the capacity to deal with massive data, a familiar DataFrame or SQL API and the rich Spark UI which allows you to monitor and track the performance of your jobs in real time.
It’s worth noting that Spark will need a dedicated compute cluster to run, which is usually costly in production. At the same time, Spark is extremely configurable, and if you know how to tune Spark properly, you’ll get some giant performance improvements.
val spark = SparkSession.builder()
.appName("Word count")
.master("local[*]")
.getOrCreate()
val streamingDF = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "your-kafka-broker:9092")
.option("subscribe", "myTopic")
.load()
val wordCount = streamingDF
.selectExpr("cast(value as string) as word")
.groupBy("word")
.count()
wordCount.writeStream
.format("console")
.outputMode("append")
.start()
.awaitTermination()
So let’s go though the standard word counting application and in here we will use the high-level Structured Streaming API. Clean and separable. Let’s break it down
val spark = SparkSession.builder()
.appName("Word count")
.master("local[*]")
.getOrCreate()
The only boilerplate you’ll need is to start a Spark Session. After that…
val streamingDF = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "your-kafka-broker:9092")
.option("subscribe", "myTopic")
.load()
…you can read your data by specifying the data source to read from, and Spark Streaming naturally supports Kafka out of the box.
val wordCount = streamingDF
.selectExpr("cast(value as string) as word")
.groupBy("word")
.count()
The actual logic is also plain and simple. In SQL, that’s just a “group by” with a count, which we are doing here. Because Kafka stores data in binary, we have to add a cast at the beginning.
wordCount.writeStream
.format("console")
.outputMode("append")
.start()
.awaitTermination()
Finally, all you have to do is to point the stream to an output sink (where again we can use Kafka) and just start the streaming query.
So let’s discuss the ups and downs with Spark Streaming.
Spark Streaming was built for big data from day 1. It offers fault-tolerance as the original Spark core and two APIs for dealing with data: one low-level high-control with DStreams and one hands-off with a familiar structure in the form of DataFrames and SQL. One nice feature of Spark is the ability to deal with late data based on event time and watermarks, which is very powerful in real life. Spark is highly configurable with massive perf benefits if used right and can connect to Kafka via its built-in connector either as data input or data output. Not least, Spark also benefits from a massive community with excellent documentation and help. As an added benefit, Spark can also be quickly spun up locally for smaller data processing.
As with the other frameworks, Spark is not perfect, though. The DataFrame and SQL APIs are cushy and familiar, but as a functional programmer I get a small stomach squeeze because some type safety is lost at compile time. Of course, you have Datasets, but then you lose some performance if you pour in lambdas. Spark Streaming is very good for big data and micro-batch processing, but it’s currently not stellar at low-latency race unless you use the continuous mode which offers few guarantees and is experimental as we speak. Lastly, Spark will need a dedicated cluster to run, so depending on your needs, you might be forced to spend a little more on compute if you go down this route.
Now the final piece: when should you use what? Naturally, every framework was built with a certain intent and we’ll lay them here.
Akka Streams is best for high-performance systems, when you want to bake Akka Streams into your application. It has an extremely powerful API, but unless you know what you’re doing, it might be easy to shoot yourself (accidentally or not).
Kafka on the other hand works best as an external high performance message bus for your applications, so if you want microservices to read and write to and from a common event store, you might be best with Kafka. However, its Java-style API is cumbersome, but I understand it might be a matter of code cleanliness and taste.
Finally, Spark Streaming is without a doubt best for big data computation. Spark has always been good at that and here we also removed data bounds. However, at the moment of this recording, Spark Streaming is bad for actual application logic and low-latency, so you might want to use it as a data aggregator to gather insights from your data.
As a bonus, everyone works with Kafka so if you want to add Kafka to your party, you can do that no matter which tool you pick.
Share on: