Giannis Polyzos
11 min read •

Share on:
In today’s modern data era there is an ever-increasing demand for delivering data insights as fast as possible. What happens “now”, might be irrelevant a few minutes or even seconds later and so there is an ever-increasing need for events to be ingested and processed as fast as possible, whether it is to improve a business and make it more competitive in a demanding market or make a system grow and adapt itself based on the environment stimulations it receives.
Along with that and the evolution of containers and cloud infrastructure companies seek ways to leverage and adopt cloud-native approaches. Moving to the cloud and adopting containers for our system means we are most likely leveraging technologies like Kubernetes for all of it’s amazing features. Having our infrastructure on the cloud and adopting cloud-native solutions means we also want our messaging and streaming solutions to be in-line with these principles.
In this blog post we will go through how you can implement cloud-native event stream processing with Apache Pulsar and Scala. We will review what Apache Pulsar has to offer in this modern data era, what makes it stand out and how you can get started with it by creating some simple Producers and Consumers using Scala and the pulsar4s library.
As described in the documentation:
Apache Pulsar is a cloud-native, distributed messaging and streaming platform that manages hundreds of billions of events per day.
It was originally created at Yahoo in 2013 to meet their enormous scaling requirements - the engineering team also reviewed solutions like Apache Kafka at the time (although those systems have grown a lot since), but didn’t quite meet their needs.
They were missing features like geo-replication, multi-tenancy and offset management along with performance under message backlog conditions - and so Apache Pulsar was born.
Let’s take a closer look at what makes it stand out:
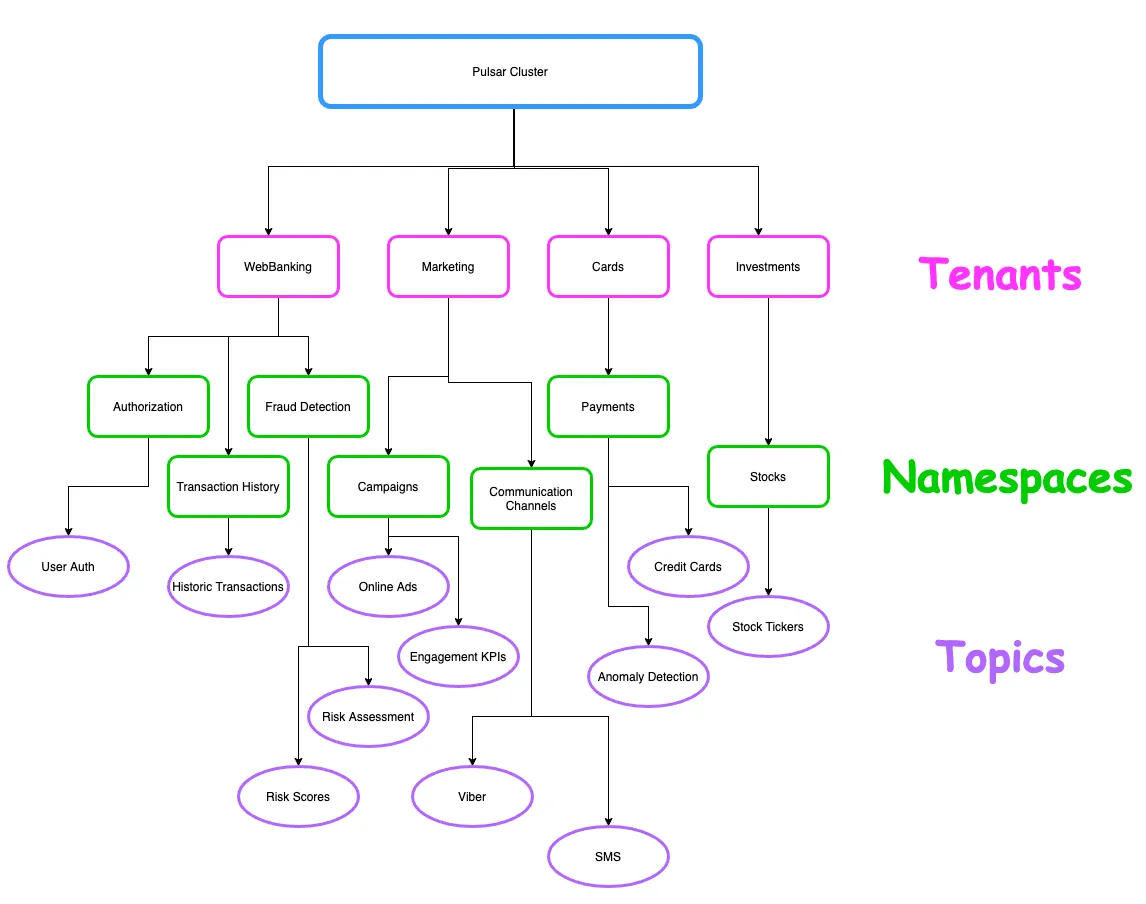
There are more features of Apache Pulsar like a built-in Schema Registry, support for transactions and Pulsar SQL, but at this point let’s see how you can actually get Pulsar up and running and create our very first Producers and Consumers in Scala.
As a simple example use case we will create a Producer that simulates sensor event readings, sends them over to a topic and then on the other end create a consumer that subscribes to that topic and just reads the incoming events. We will be using the pulsar4s client library for our implementation and we will run a Pulsar cluster using docker. In order to start a Pulsar cluster in standalone mode, run the following command within your terminal:
docker run -it \
-p 6650:6650 \
-p 8080:8080 \
--name pulsar \
apachepulsar/pulsar:2.8.0 \
bin/pulsar standalone
This command will start Pulsar and bind the necessary ports to your local machine. With our cluster up and running, let’s start creating our producers and consumers.
First, we need the dependencies for the pulsar4s-core and pulsar4s-circe - so let’s add the following to our build.sbt file:
val pulsar4sVersion = "2.7.3"
lazy val pulsar4s = "com.sksamuel.pulsar4s" %% "pulsar4s-core" % pulsar4sVersion
lazy val pulsar4sCirce = "com.sksamuel.pulsar4s" %% "pulsar4s-circe" % pulsar4sVersion
libraryDependencies ++= Seq(
pulsar4s, pulsar4sCirce
)
Then we will define the message payload for a sensor event as follows:
case class SensorEvent(sensorId: String,
status: String,
startupTime: Long,
eventTime: Long,
reading: Double)
We also need the following imports in scope:
import com.sksamuel.pulsar4s.{DefaultProducerMessage, EventTime, ProducerConfig, PulsarClient, Topic}
import io.ipolyzos.models.SensorDomain
import io.ipolyzos.models.SensorDomain.SensorEvent
import io.circe.generic.auto._
import com.sksamuel.pulsar4s.circe._
import scala.concurrent.ExecutionContext.Implicits.global
The main entry point for all producing and consuming applications is the Pulsar Client, which handles the connection to the brokers. From within the Pulsar client you can also set up the authentication to your cluster as well as other important tuning configurations such as timeout settings and connection pools. You can simply instantiate the client by providing the service url you want to connect to.
val pulsarClient = PulsarClient("pulsar://localhost:6650")
With our client in place let’s take a look at the producer initialization and the producer loop.
val topic = Topic("sensor-events")
// create the producer
val eventProducer = pulsarClient.producer[SensorEvent](ProducerConfig(
topic,
producerName = Some("sensor-producer"),
enableBatching = Some(true),
blockIfQueueFull = Some(true))
)
// sent 100 messages
(0 until 100) foreach { _ =>
val sensorEvent = SensorDomain.generate()
val message = DefaultProducerMessage(
Some(sensorEvent.sensorId),
sensorEvent,
eventTime = Some(EventTime(sensorEvent.eventTime)))
eventProducer.sendAsync(message) // use the async method to sent the message
}
There are a few things to note here:
.sendAsync() method to send the messages to Pulsar. This will send the message without waiting for an acknowledgement and since we buffer messages to the queue this can overwhelm the client.blockIfQueueFull applies backpressure and informs the producer to wait before sending more messages.sensorId as the key of the message, the value of sensorEvent and we also provide the eventTime i.e the time the event was produced.At this point we have our producer in place to start sending messages to Pulsar. A complete implementation can be found here.
Now let’s switch our focus to the consuming side. Much like we did with the producing side, the consuming side needs to have a Pulsar Client in scope.
val consumerConfig = ConsumerConfig(
Subscription("sensor-event-subscription"),
Seq(Topic("sensor-events")),
consumerName = Some("sensor-event-consumer"),
subscriptionInitialPosition = Some(SubscriptionInitialPosition.Earliest),
subscriptionType = Some(SubscriptionType.Exclusive)
)
val consumerFn = pulsarClient.consumer[SensorEvent](consumerConfig)
var totalMessageCount = 0
while (true) {
consumerFn.receive match {
case Success(message) =>
consumerFn.acknowledge(message.messageId)
totalMessageCount += 1
println(s"Total Messages '$totalMessageCount - Acked Message: ${message.messageId}")
case Failure(exception) =>
println(s"Failed to receive message: ${exception.getMessage}")
}
}
Let’s take things in turn:
As mentioned during the blog post, Apache Pulsar provides unification of both messaging and streaming patterns and it does so, by providing different subscription types.
We have the following subscription types:
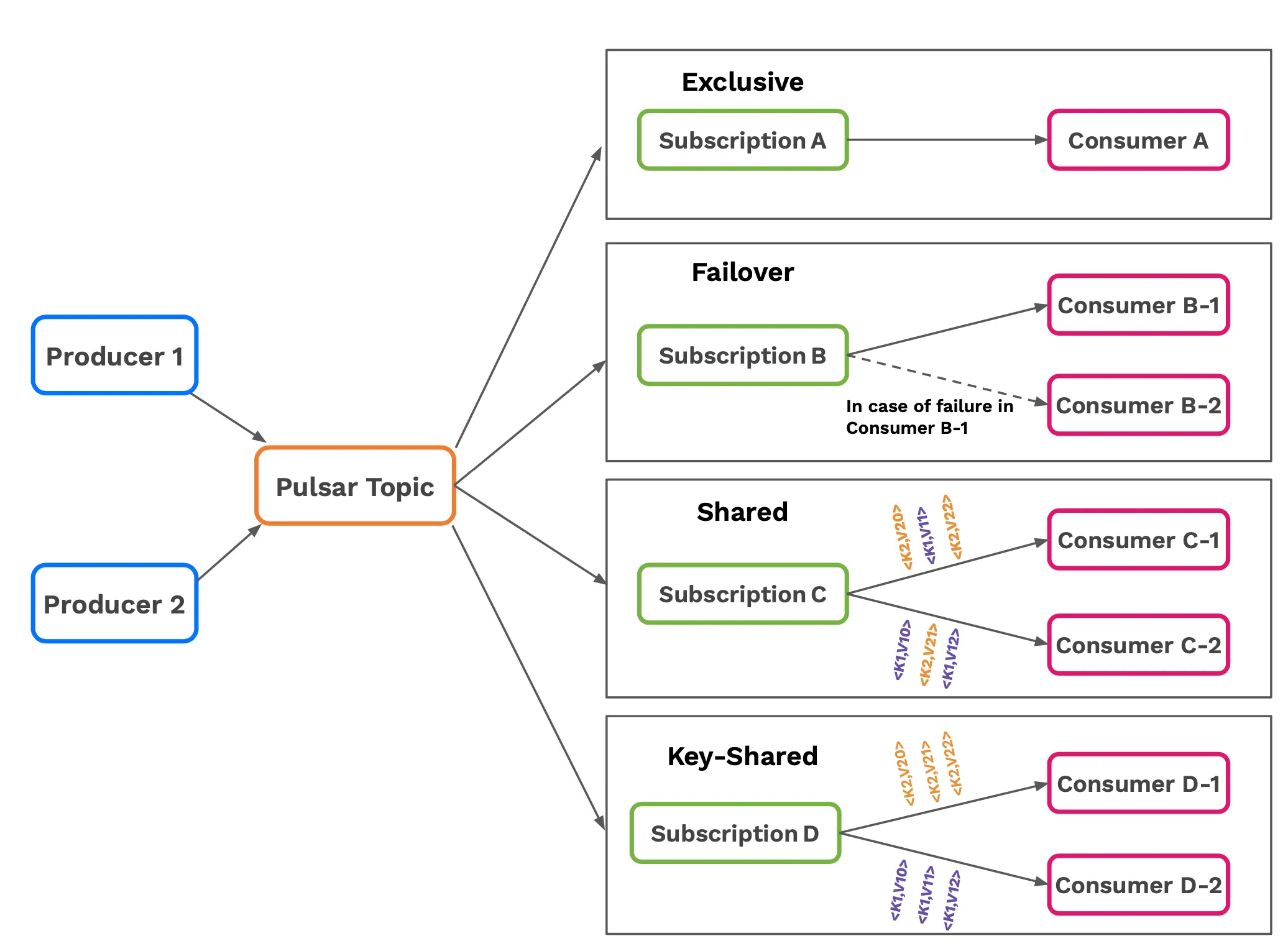
Different Subscription types are used for different use cases. For example in order to implement a typical fan-out messaging pattern you can use the exclusive or failover subscription types. For message queueing and work queues a good candidate is Shared Subscription in order to share the work among multiple consumers. On the other hand for streaming use cases and/or key-based stream processing the Failover and KeyShared subscriptions can be a good candidate that can allow for ordered consumption or scale your processing based on some key.
In this blog post we made a brief introduction at what Apache Pulsar is, what makes it stand out as a new messaging and streaming platform alternative, how you can create some really simple producing and consuming applications and finally we highlighted how it unified messaging and streaming through different subscription modes.
If this overview sparked your interest and want to learn more, I encourage you to take a look at Pulsar IO (moves data in and out of Pulsar easily), Pulsar Functions (Pulsar’s serverless and lightweight compute framework), which you can use to apply your processing logic on your Pulsar topics, reduce all the boilerplate code needed for producing and consuming applications and combined with Function Mesh make your event streaming truly cloud-native, by leveraging Kubernetes native features like deployments and autoscaling.
Share on: