Riccardo Cardin
31 min read •

Share on:
The vast majority of applications today connect with some form of a persistent layer, and, sooner or later, every developer faces the challenge of connecting to a database. We rely on the JDBC specification if we need to connect to SQL databases in the JVM ecosystem. However, JDBC is not a good fit if we use functional programming since the library performs a lot of side effects. Fortunately, a library called doobie provides a higher-level API on top of JDBC, using an effectful style through the Cats and Cats Effect libraries.
So, without further ado, let’s introduce the doobie library.
As usual, we’ll start by importing the libraries we need in the sbt file. We will use Postgres as our database of reference:
val DoobieVersion = "1.0.0-RC1"
val NewTypeVersion = "0.4.4"
libraryDependencies ++= Seq(
"org.tpolecat" %% "doobie-core" % DoobieVersion,
"org.tpolecat" %% "doobie-postgres" % DoobieVersion,
"org.tpolecat" %% "doobie-hikari" % DoobieVersion,
"io.estatico" %% "newtype" % NewTypeVersion
)
As we said, doobie is a library that lives in the Cats ecosystem. However, the dependencies to Cats and Cats Effects are already contained in the doobie library. Version 1.0.0-RC1 of doobie uses the Cats Effect version 3.
Since we chose to use Postgres as our database, we need to spin up a Postgres instance. We will use the Postgres Docker image to do this. To simplify the process, we define the Postgres image in a docker-compose.yml file:
version: "3.1"
services:
db:
image: postgres
restart: always
volumes:
- "./sql:/docker-entrypoint-initdb.d"
environment:
- "POSTGRES_USER=docker"
- "POSTGRES_PASSWORD=docker"
ports:
- "5432:5432"
adminer:
image: adminer
restart: always
ports:
- 8080:8080
The above configuration defines a Postgres instance listening on port 5432 and having a user, admin, with password example. We mount a directory sql containing the SQL scripts to be executed on startup, and that we will define in a moment.
Moreover, we define an Adminer instance listening on port 8080. Adminer is a web interface to Postgres, which we will use to create a database, some tables, and populate them with some data.
Next, we need a use case to train our skills about doobie. We will use the same use case we introduced in the article http4s: Unleashing the Power of HTTP APIs Library, which is implementing a small IMDB-like web service. The primary domain objects of the service are movies, actors, and directors. The goal is to use doobie to interact with these tables through queries, insertion, and updates.
Inside Postgres, we will model the domain objects as tables and define their relations as foreign keys. The tables will be named movies, actors, and directors:
-- Database
CREATE DATABASE myimdb;
\c myimdb;
-- Directors
CREATE TABLE directors (
id serial NOT NULL,
PRIMARY KEY (id),
name character varying NOT NULL,
last_name character varying NOT NULL
);
-- Movies
CREATE TABLE movies (
id uuid NOT NULL,
title character varying NOT NULL,
year_of_production smallint NOT NULL,
director_id integer NOT NULL
);
ALTER TABLE movies
ADD CONSTRAINT movies_id PRIMARY KEY (id);
ALTER TABLE movies
ADD FOREIGN KEY (director_id) REFERENCES directors (id);
-- Actors
CREATE TABLE actors (
id serial NOT NULL,
PRIMARY KEY (id),
name character varying NOT NULL
);
-- Link between movies and actors
CREATE TABLE movies_actors (
movie_id uuid NOT NULL,
actor_id integer NOT NULL
);
ALTER TABLE movies_actors
ADD CONSTRAINT movies_actors_id_movies_id_actors PRIMARY KEY (movie_id, actor_id);
ALTER TABLE movies_actors
ADD FOREIGN KEY (movie_id) REFERENCES movies (id);
ALTER TABLE movies_actors
ADD FOREIGN KEY (actor_id) REFERENCES actors (id);
The ER diagram associated with the above tables’ definition is the following:
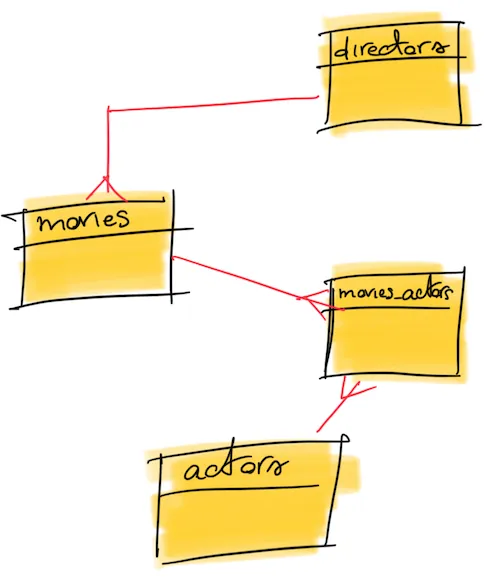
Then, we need to populate the above tables with some data. As in the previous article, we renew our love for the movie “Zack Snyder’s Justice League”:
-- Actors
INSERT INTO actors (name) VALUES ('Henry Cavill');
INSERT INTO actors (name) VALUES ('Gal Godot');
INSERT INTO actors (name) VALUES ('Ezra Miller');
INSERT INTO actors (name) VALUES ('Ben Affleck');
INSERT INTO actors (name) VALUES ('Ray Fisher');
INSERT INTO actors (name) VALUES ('Jason Momoa');
COMMIT;
-- Directors
INSERT INTO directors (name, last_name)
VALUES ('Zack', 'Snyder');
COMMIT;
-- Movies
INSERT INTO movies (id, title, year_of_production, director_id)
VALUES ('5e5a39bb-a497-4432-93e8-7322f16ac0b2', 'Zack Snyder''s Justice League', '2021', 1);
COMMIT;
-- Actor-Movie link
INSERT INTO movies_actors (movie_id, actor_id)
VALUES ('5e5a39bb-a497-4432-93e8-7322f16ac0b2', 1);
INSERT INTO movies_actors (movie_id, actor_id)
VALUES ('5e5a39bb-a497-4432-93e8-7322f16ac0b2', 2);
INSERT INTO movies_actors (movie_id, actor_id)
VALUES ('5e5a39bb-a497-4432-93e8-7322f16ac0b2', 3);
INSERT INTO movies_actors (movie_id, actor_id)
VALUES ('5e5a39bb-a497-4432-93e8-7322f16ac0b2', 4);
INSERT INTO movies_actors (movie_id, actor_id)
VALUES ('5e5a39bb-a497-4432-93e8-7322f16ac0b2', 5);
INSERT INTO movies_actors (movie_id, actor_id)
VALUES ('5e5a39bb-a497-4432-93e8-7322f16ac0b2', 6);
COMMIT;
In Scala, we will use the following classes to define the domain objects:
case class Actor(id: Int, name: String)
case class Movie(id: String, title: String, year: Int, actors: List[String], director: String)
// We will define the Director class later in the article. NO SPOILER!
Finally, all the examples contained in the article will use the following imports:
import cats.data.NonEmptyList
import cats.effect._
import cats.implicits._
import doobie._
import doobie.implicits._
import io.estatico.newtype.macros.newtype
import java.util.UUID
// Very important to deal with arrays
import doobie.postgres._
import doobie.postgres.implicits._
import doobie.util.transactor.Transactor._
So, with the above solid background, we can now enter the world of doobie.
The first thing we need to work on within a database is retrieving a connection. In doobie, handling the connection is done with a doobie.util.transactor.Transactor. There are many ways to create an instance of a Transactor. The easiest is to use the Transactor.fromDriverManager method, which will create a Transactor from a JDBC driver manager:
val xa: Transactor[IO] = Transactor.fromDriverManager[IO](
"org.postgresql.Driver",
"jdbc:postgresql:myimdb",
"docker", // username
"docker" // password
)
This approach is the most straightforward, but it is not the most efficient. The reason is that the JDBC driver manager will try to load the driver for each connection, which can be pretty expensive. Moreover, the driver manager has no upper bound on the number of connections it will create. However, while experimenting and testing doobie features, this approach works quite well.
// doobie library's code
// The ev variable is an instance of Async[IO]
val acquire = ev.blocking{ Class.forName(driver); conn() }
In production code, as we said, we don’t want to use an instance of Transactor coming directly from the JDBC driver manager. Instead, we will use a Transactor that is backed by a connection pool. doobie integrates well with the HikariCP connection pool library through the doobie-hikari module. Since a connection pool is a resource with its own lifecycle, we will use the Cats Effect Resource type to manage it:
val postgres: Resource[IO, HikariTransactor[IO]] = for {
ce <- ExecutionContexts.fixedThreadPool[IO](32)
xa <- HikariTransactor.newHikariTransactor[IO](
"org.postgresql.Driver",
"jdbc:postgresql:myimdb",
"postgres",
"example", // The password
ce
)
} yield xa
We will directly use the Transactor coming from the JDBC driver manager in most article examples. In the last part, we will focus on using the Resource type to manage the connection pool.
Now that we learned how to connect to a database, we can start querying it. The most straightforward query we can do is to retrieve all actors names in the database, since the query doesn’t request any input parameter, and extract only one column:
def findAllActorsNamesProgram: IO[List[String]] = {
val findAllActorsQuery: doobie.Query0[String] = sql"select name from actors".query[String]
val findAllActors: doobie.ConnectionIO[List[String]] = findAllActorsQuery.to[List]
findAllActors.transact(xa)
}
As it’s the first query we make, the code is really verbose. However, we can analyze every aspect of a query in this way.
First, the sql interpolator allows us to create SQL statement fragments (more to come). Next, the method query lets us create a type that maps the single-row result of the query in a Scala type. The class is called Query0[A]. To accumulate results into a list, we use the to[List] method, which creates a ConnectionIO[List[String]].
The ConnectionIO[A] type is interesting since it introduces a typical pattern used in the doobie library. In fact, doobie defines all its most essential types as instances of the Free monad.
Although the description and profound comprehension of the free monad is behind the scope of this article, we can say that a program with the type ConnectionIO[A] represents a computation that, given a Connection, will generate a value of type IO[A].
Every free monad is only a description of a program. It’s not executable at all since it requires an interpreter. The interpreter, in this case, is the Transactor we created. Its role is to compile the program into a Kleisli[IO, Connection, A]. The course on Cats explains Kleisli in depth, but in short, the previous Kleisli is another representation of the function Connection => IO[A].
So, given an instance of IO[Connection] to the Kleisli through the transact method, we can execute the compiled program into the desired IO[A], and then run it using the Cats Effect library:
object DoobieApp extends IOApp {
val xa: Transactor[IO] = Transactor.fromDriverManager[IO](
"org.postgresql.Driver",
"jdbc:postgresql:myimdb",
"docker",
"docker"
)
def findAllActorsNamesProgram: IO[List[String]] = {
val findAllActorsQuery: doobie.Query0[String] = sql"select name from actors".query[String]
val findAllActors: doobie.ConnectionIO[List[String]] = findAllActorsQuery.to[List]
findAllActors.transact(xa)
}
override def run(args: List[String]): IO[ExitCode] = {
findAllActorsNamesProgram()
.map(println)
.as(ExitCode.Success)
}
}
Given the information we initially stored in the database, the above code produces the following output:
List(Henry Cavill, Gal Godot, Ezra Miller, Ben Affleck, Ray Fisher, Jason Momoa)
If we know for sure that the query will return exactly one row, we can use the unique method:
def findActorByIdProgram(id: Int): IO[Actor] = {
val findActorById: doobie.ConnectionIO[Actor] =
sql"select id, name from actors where id = $id".query[Actor].unique
findActorById.transact(xa)
}
However, if the query doesn’t return any row, we will get an exception. So, we can safely use the option method and let the program return an Option[Actor]:
def findActorByIdProgram(id: Int): IO[Option[Actor]] = {
val findActorById: doobie.ConnectionIO[Option[Actor]] =
sql"select id, name from actors where id = $id".query[Actor].option
findActorById.transact(xa)
}
Although extracting actors in a List[String] seems legit at first sight, it’s not safe in a real-world scenario. In fact, the number of extracted rows could be too much for the memory allocated to the application. For this reason, we should use a Stream instead of a List. doobie integrates smoothly with the functional streaming library fs2. Again, describing how fs2 works is behind the scope of this article, and we just focus on how to use it with doobie.
For example, let’s change the above example to use the streaming API:
val actorsNamesStream: fs2.Stream[doobie.ConnectionIO, String] =
sql"select name from actors".query[String].stream
The stream method on the type Query0 returns a Stream[ConnectionIO, A] which means a stream containing instances of type A, wrapped in an effect of type ConnectionIO (for a brief explanation of the Effect pattern, please refer to The Effect Pattern).
Once we obtained an instance of a Stream, we can decide to return it to the caller as it is, or to compile it into a finite type, such as List[String] or Vector[String]:
val actorsNamesList: IO[List[String]] = actorsNamesStream.compile.toList.transact(xa)
Clearly, there are more than single-column queries. In fact, doobie can handle multi-column queries as well. For example, let’s query the ids and names of all the actors and return them as a tuple:
def findAllActorsIdsAndNamesProgram: IO[List[(Int, String)]] = {
val query: doobie.Query0[(Int, String)] = sql"select id, name from actors".query[(Int, String)]
val findAllActors: doobie.ConnectionIO[List[(Int, String)]] = query.to[List]
findAllActors.transact(xa)
}
We can map the query result inside an instance of an HList or inside an Option. However, as we can imagine, the most helpful mapping of returned columns is directly into a class. Let’s say we want to store the information of extracted actors directly into instances of the class Actor class:
def findAllActorsProgram: IO[List[Actor]] = {
val findAllActors: fs2.Stream[doobie.ConnectionIO, Actor] =
sql"select id, name from actors".query[Actor].stream
findAllActors.compile.toList.transact(xa)
}
doobie can map the tuple of extracted columns directly into a case class. For now, let’s assume that the mapping between the extracted tuple and the properties of the case class must be one-to-one. In the last part of the article, we will introduce the type classes that allow the conversion of a tuple into a case class.
One last thing about selecting information from a table is to add parameters to the query. Fortunately, the sql interpolator works smoothly with parameters, using the exact mechanism used by Scala native String interpolation:
def findActorsByNameInitialLetterProgram(initialLetter: String): IO[List[Actor]] = {
val findActors: fs2.Stream[doobie.ConnectionIO, Actor] =
sql"select id, name from actors where LEFT(name, 1) = $initialLetter".query[Actor].stream
findActors.compile.toList.transact(xa)
}
The above program extracts all actors from the table whose names start with the given initial letter. As we can see, passing a parameter to a query is as simple as passing it to an interpolated string.
HC ModuleThe interpolator sql is a very handy syntax for writing SQL queries. However, it’s not the only way to write queries. In fact, it’s just an API, implemented in terms of the functions available in the doobie.hi.connection module, aliased as HC.
So, let’s take the first program we developed above, the findAllActorsNamesProgram, and desugar it using the HC module:
def findActorByNameUsingHCProgram(actorName: String): IO[Option[Actor]] = {
val query = "select id, name from actors where name = ?"
HC.stream[Actor](
query,
HPS.set(actorName), // Parameters start from index 1 by default
512
).compile
.toList
.map(_.headOption)
.transact(xa)
}
First, the query becomes a plain String containing ? wildcards. The sql interpolator is just syntactic sugar for the HC.stream[A] method. Leaving the comprehension of the first parameter to the reader, the second parameter has type PreparedStatementIO[B]. As for the ConnectionIO[A] type, a PreparedStatementIO is an instance of the free monad pattern. In this case, it describes how to inject parameters into the query. So, the interpreter of the monad, HC, builds a Kleisli[IO, PreparedStatement, A], which is precisely a function returning an IO[A] given a PreparedStatement.
The third parameter is the maximum number of rows to be fetched at a time. In fact, doobie reads rows in chunks.
If the query has more than one parameter, we have many choices on the syntax to use:
// Set parameters as (Int, String)
HPS.set((1, "Henry Cavill"))
// Set parameters individually
HPS.set(1, 1) *> HPS.set(2, "Henry Cavill")
// ...and many others!
Until now, we used the sql interpolator to build our queries. It turns out that the sql interpolator is an alias of the more general fr interpolator, whose name stands for `Fragment. A fragment is a piece of an SQL statement that we can combine with any other fragment to build a proper SQL instruction.
Imagine building the query at runtime, extracting the list of actors whose names start with a given initial letter. Using fragments, we can do it as follows:
def findActorsByInitialLetterUsingFragmentsProgram(initialLetter: String): IO[List[Actor]] = {
val select: Fragment = fr"select id, name"
val from: Fragment = fr"from actors"
val where: Fragment = fr"where LEFT(name, 1) = $initialLetter"
val statement = select ++ from ++ where
statement.query[Actor].stream.compile.toList.transact(xa)
}
In the example above, we build the three parts of the SQL statements, and then we combine them to produce the final query using the ++ operator. It’s easy to understand why Fragment is also a Monoid since it’s possible to use the ++ operator to define the combine function of monoids (more on the article Semigroups and Monoids in Scala):
// doobie library's code
object fragment {
implicit val FragmentMonoid: Monoid[Fragment] =
new Monoid[Fragment] {
val empty = Fragment.empty
def combine(a: Fragment, b: Fragment) = a ++ b
}
}
So, if we want to use the combination operator |+|, made available by the monoid instance, we can rewrite the previous example as follows:
def findActorsByInitialLetterUsingFragmentsAndMonoidsProgram(initialLetter: String): IO[List[Actor]] = {
import cats.syntax.monoid._
val select: Fragment = fr"select id, name"
val from: Fragment = fr"from actors"
val where: Fragment = fr"where LEFT(name, 1) = $initialLetter"
val statement = select |+| from |+| where
statement.query[Actor].stream.compile.toList.transact(xa)
}
As we say, fragments are helpful to build queries dynamically. One widespread use case is to create a query that uses the IN operator since JDBC doesn’t give any built-in support for this kind of operator. Fortunately, doobie does it, providing a reliable method in the Fragments object:
def findActorsByNamesProgram(actorNames: NonEmptyList[String]): IO[List[Actor]] = {
val sqlStatement: Fragment =
fr"select id, name from actors where " ++ Fragments.in(fr"name", actorNames) // name IN (...)
sqlStatement.query[Actor].stream.compile.toList.transact(xa)
}
Indeed, the Fragments object contains a lot of valuable functions to implement many recurring SQL queries patterns:
// doobie library's code
val Fragments = doobie.util.fragments
object fragments {
/** Returns `(f1) AND (f2) AND ... (fn)`. */
def and(fs: Fragment*): Fragment = ???
/** Returns `(f1) OR (f2) OR ... (fn)`. */
def or(fs: Fragment*): Fragment = ???
/** Returns `WHERE (f1) AND (f2) AND ... (fn)` or the empty fragment if `fs` is empty. */
def whereAnd(fs: Fragment*): Fragment = ???
/** Returns `WHERE (f1) OR (f2) OR ... (fn)` or the empty fragment if `fs` is empty. */
def whereOr(fs: Fragment*): Fragment = ???
// And many more...
}
While experimenting with the library, passing the Transactor instance around could seem a little overwhelming. Moreover, the syntax transact(xa) is a bit cumbersome. Adding that it’s widespread to print out the program’s results to the console, the library will help us do that. Please, welcome the YOLO mode!
First, we need a stable reference to the Transactor instance. Then we can import the yolo module:
val y = xa.yolo
import y._
Then, imagine we want to find all actors in the database and print them out. Using the yolo syntax, we can write the following program:
object YoloApp extends App {
import cats.effect.unsafe.implicits.global
val xa: Transactor[IO] = Transactor.fromDriverManager[IO](
"org.postgresql.Driver",
"jdbc:postgresql:myimdb",
"docker",
"docker"
)
val y = xa.yolo
import y._
val query = sql"select name from actors".query[String].to[List]
query.quick.unsafeRunSync()
}
As we can see, the program doesn’t need an IOApp to execute. Then, the quick method is syntactic sugar for calling the transact method, which is a bit more verbose and then sinking the stream to standard output.
Remember, You Only Load Once!
The other side of the moon of the database world is mutating the tables and the data they contain. doobie offers support not only for queries but also for insertions, updates, deletions, and changes on tables’ structure.
It should not come as a surprise that inserting follows the same pattern of selecting rows from tables. For example, let’s save a new actor inside the actors table:
def saveActorProgram(name: String): IO[Int] = {
val saveActor: doobie.ConnectionIO[Int] =
sql"insert into actors (name) values ($name)".update.run
saveActor.transact(xa)
}
As we can see, we continue to use the sql interpolator and its capabilities of dealing with input parameters. However, the update method returns an instance of the Update0 class. It corresponds to the Query0 class in the case of DMLs.
We need to call one available method to get a ConnectionIO from an Update0. The easiest way to do this is to call the run method, which returns the number of updated rows inside the ConnectionIO.
Moreover, it’s possible to get back the autogenerated id of the inserted row, using the withUniqueGeneratedKeys method and specifying the column name:
def saveActorAndGetIdProgram(name: String): IO[Int] = {
val saveActor: doobie.ConnectionIO[Int] =
sql"insert into actors (name) values ($name)"
.update.withUniqueGeneratedKeys[Int]("id")
saveActor.transact(xa)
}
Now that we know how to insert and retrieve information from a table, we can create a program that both inserts and retrieves an actor in sequence:
def saveAndGetActorProgram(name: String): IO[Actor] = {
val retrievedActor = for {
id <- sql"insert into actors (name) values ($name)".update.withUniqueGeneratedKeys[Int]("id")
actor <- sql"select * from actors where id = $id".query[Actor].unique
} yield actor
retrievedActor.transact(xa)
}
Here, we use the fact that the type ConnectionIO[A] is a monad, which means we can chain operations on it through a sequence of calls to flatMap and map methods.
doobie allows us to insert more than one row at a time. However, to do so, we have to desugar the sql interpolator and the subsequent call to the run method. So, let’s first remove the syntactic sugar:
val name = "John Travolta"
// This statement...
sql"insert into actors (name) values ($name)".update.run
// ...is equivalent to this one:
val stmt = "insert into actors (name) values (?)"
Update[String](stmt).run(name)
Now, we can use the desugared version of the sql interpolator to insert multiple rows. As an example, we can insert a list of actors into the database:
def saveActorsProgram(actors: NonEmptyList[String]): IO[Int] = {
val insertStmt: String = "insert into actors (name) values (?)"
val numberOfRows: doobie.ConnectionIO[Int] = Update[String](insertStmt).updateMany(actors.toList)
numberOfRows.transact(xa)
}
As we can see, doobie gives us a method, updateMany, to execute a batch insertion. It takes a list of parameters and returns the number of rows inserted. Some databases, such as Postgres, can produce a list of column values of the inserted rows. In this case, we can use the method updateManyWithGeneratedKeys, taking as input a list of column names:
def saveActorsAndReturnThemProgram(actors: NonEmptyList[String]): IO[List[Actor]] = {
val insertStmt: String = "insert into actors (name) values (?)"
val actorsIds = Update[String](insertStmt).updateManyWithGeneratedKeys[Actor]("id", "name")(actors.toList)
actorsIds.compile.toList.transact(xa)
}
Updating information in the database is the same affair as inserting. There are no substantial differences between the two. Imagine we want to fix the year of production of the movie “Zack Snyder’s Justice League”. Here is how we can do it:
def updateJLYearOfProductionProgram(): IO[Int] = {
val year = 2021
val id = "5e5a39bb-a497-4432-93e8-7322f16ac0b2"
sql"update movies set year_of_production = $year where id = $id".update.run.transact(xa)
}
Finally, the deletion follows the same pattern. Use the keyword delete instead of insert or update inside the sql interpolator.
So far, we have seen many examples of usages of the sql interpolator, which magically can convert Scala types into JDBC types when reading input parameters, and vice versa when concerning mapping values extracted from the database.
As we can imagine, there is no magic whatsoever. As skilled Scala developers, we should have known that there are some type classes behind it whenever someone talks about magic.
In fact, doobie basically uses four type classes for the conversion between Scala and JDBC types: Get[A], Put[A], Read[A] and Write[A].
The Get[A] describes creating the Scala type A from a non-nullable database value. We can also apply the same type class to obtain type Option[A]. So, doobie uses an instance of Get[A] to map the results of a query into Scala.
The Put[A] type class describes creating a non-nullable database value from the Scala type A. As for the Get[A], the Put[A] type class maps also the Option[A] type.
doobie defines the instances of the above type classes for the following types (directly from the doobie documentation):
Byte, Short, Int, Long, Float, and Double;BigDecimal (both Java and Scala versions);Boolean, String, and Array[Byte];Date, Time, and Timestamp from the java.sql package;Date from the java.util package;Instant, LocalDate, LocalTime, LocalDateTime, OffsetTime, OffsetDateTime and ZonedDateTime from the java.time package; andDeriving the Get and Put type classes for types that don’t fit into one of the above categories is relatively easy. To create a concrete example, we introduce in our project the estatico/scala-newtype, which allows creating a new type that is a subtype of the original type but with a different name. The description of newtypes is far beyond the scope of this article, but you can find a good introduction on Value Classes in Scala Explained.
First, let’s create a newtype wrapper around an actor name:
@newtype case class ActorName(value: String)
Now, we can try to use the newtype to map the result of a query:
def findAllActorNamesProgram(): IO[List[ActorName]] = {
sql"select name from actors".query[ActorName].to[List].transact(xa)
}
As we can expect, when we try to compile the above code, we get an error since the compiler cannot find any suitable type classes instances for the ActorName type:
[error] Cannot find or construct a Read instance for type:
[error]
[error] DoobieApp.ActorName
[error]
[error] This can happen for a few reasons, but the most common case is that a data
[error] member somewhere within this type doesn't have a Get instance in scope. Here are
[error] some debugging hints:
[error]
[error] - For Option types, ensure that a Read instance is in scope for the non-Option
[error] version.
[error] - For types you expect to map to a single column ensure that a Get instance is
[error] in scope.
[error] - For case classes, HLists, and shapeless records ensure that each element
[error] has a Read instance in scope.
[error] - Lather, rinse, repeat, recursively until you find the problematic bit.
[error]
[error] You can check that an instance exists for Read in the REPL or in your code:
[error]
[error] scala> Read[Foo]
[error]
[error] and similarly with Get:
[error]
[error] scala> Get[Foo]
[error]
[error] And find the missing instance and construct it as needed. Refer to Chapter 12
[error] of the book of doobie for more information.
[error] sql"select name from actors".query[ActorName].to[List].transact(xa)
Fortunately, doobie gives us all the tools to quickly create such type classes. The first method we can use is to derive the Get[ActorName] and Put[ActorName] type classes from the same defined for the String type:
object ActorName {
implicit val actorNameGet: Get[ActorName] = Get[String].map(ActorName(_))
implicit val actorNamePut: Put[ActorName] = Put[String].contramap(actorName => actorName.value)
}
As we may imagine, the map method is defined in the Functor[Get] type class, whereas the contramap method is defined in the Contravariant[Put] type class:
// doobie library's code
trait GetInstances extends GetPlatform {
implicit val FunctorGet: Functor[Get] =
new Functor[Get] {
def map[A, B](fa: Get[A])(f: A => B): Get[B] =
fa.map(f)
}
}
trait PutInstances extends PutPlatform {
implicit val ContravariantPut: Contravariant[Put] =
new Contravariant[Put] {
def contramap[A, B](fa: Put[A])(f: B => A): Put[B] =
fa.contramap(f)
}
}
Moreover, in the case of newtypes, we can simplify the definition of the Get and Put type classes, using the deriving method available in the newtype library:
@newtype case class ActorName(value: String)
object ActorName {
implicit val actorNameGet: Get[ActorName] = deriving
implicit val actorNamePut: Put[ActorName] = deriving
}
Since it’s widespread to derive both type classes for a type, doobie also defines the Meta[A] type class, which allows us to create with a single statement both the Get and the Put type classes for a type:
implicit val actorNameMeta: Meta[ActorName] = Meta[String].imap(ActorName(_))(_.value)
The first parameter of the imap method is the function that defines the Get instance, whereas the second parameter is the function that defines the Put instance. The imap function comes from the Invariant[Meta] type class defined in the Cats library.
Again, since the newtype library defines the deriving method, we can simplify the definition of the Meta type class:
implicit val actorNameMeta: Meta[ActorName] = deriving
doobie uses the Get and Put type classes only to manage single-column schema types. In general, we need to map more than one column directly into a Scala class or into a tuple. For this reason, doobie defines two more type classes, Read[A] and Write[A], which can handle heterogeneous collections of columns.
The Read[A] allows us to map a vector of schema types inside a Scala type. Vice versa, the Write[A] will enable us to interact with more complex types instead of plain ints, strings etc.
Logically, the Read and Write type classes are defined as a composition of Get and Put on the attributes of the referenced type. In detail, the type can be a record (tuple), or a product type (a case class), or even an HList. In addition, doobie adds the mapping of Option[A].
In any other case, we must define a custom mapping, as we have previously done. Starting from the definition of Read and Write for a well-known type, we use the map and contramap functions to derive the needed type classes. Speaking about our movies’ database, imagine we want to read from the directors table. We can define the Scala type Director representing a single row of the table:
object domain {
@newtype case class DirectorId(id: Int)
@newtype case class DirectorName(name: String)
@newtype case class DirectorLastName(lastName: String)
case class Director(id: DirectorId, name: DirectorName, lastName: DirectorLastName)
}
Since we are well-grounded Scala developers, we defined a newtype wrapping every native type. Now, we want to get all the directors stored in the table:
def findAllDirectorsProgram(): IO[List[Director]] = {
val findAllDirectors: fs2.Stream[doobie.ConnectionIO, Director] =
sql"select id, name, last_name from directors".query[Director].stream
findAllDirectors.compile.toList.transact(xa)
}
However, as we may expect, running the above program generates an error since the compiler cannot find any type class instance for Read[Director]. So, let’s define the missing type class instances:
object Director {
implicit val directorRead: Read[Director] =
Read[(Int, String, String)].map { case (id, name, lastname) =>
Director(DirectorId(id), DirectorName(name), DirectorLastName(lastname))
}
implicit val directorWrite: Write[Director] =
Write[(Int, String, String)].contramap { director =>
(director.id.id, director.name.name, director.lastName.lastName)
}
}
Et voilà, now the program runs without any error.
Until now, we presented some very straightforward examples of queries. However, we can also handle joins. The good news is that doobie takes join between tables in a very natural way.
Let’s say we want to find a movie by its name. We want to retrieve also the director’s information and the list of actors that played in the film. Using the ER model we presented at the beginning of the article, we have to join three tables: the movies table, the directors table, and the actors table. Here is how we can implement it in doobie:
def findMovieByNameProgram(movieName: String): IO[Option[Movie]] = {
val query = sql"""
|SELECT m.id,
| m.title,
| m.year_of_production,
| array_agg(a.name) as actors,
| d.name
|FROM movies m
|JOIN movies_actors ma ON m.id = ma.movie_id
|JOIN actors a ON ma.actor_id = a.id
|JOIN directors d ON m.director_id = d.id
|WHERE m.title = $movieName
|GROUP BY (m.id,
| m.title,
| m.year_of_production,
| d.name,
| d.last_name)
|""".stripMargin
.query[Movie]
.option
query.transact(xa)
}
Since the actor table extracts many rows for every movie, we used a GROUP BY operation and the array_agg Postgres function, which creates an array from the actors’ names.
However, the array type is not SQL standard. So, to let doobie map the array type to a Scala List, we need to import the doobie.postgres._ and doobie.postgres.implicits._ packages, belonging to the doobie-postgres library.
As we said, the array type is not standard, and the database we’re using might not support arrays. In this case, the only solution left is to perform the join manually, which means splitting the original query into three different queries and joining the data programmatically:
def findMovieByNameWithoutSqlJoinProgram(movieName: String): IO[Option[Movie]] = {
def findMovieByTitle() =
sql"""
| select id, title, year_of_production, director_id
| from movies
| where title = $movieName"""
.query[(UUID, String, Int, Int)].option
def findDirectorById(directorId: Int) =
sql"select name, last_name from directors where id = $directorId"
.query[(String, String)].to[List]
def findActorsByMovieId(movieId: UUID) =
sql"""
| select a.name
| from actors a
| join movies_actors ma on a.id = ma.actor_id
| where ma.movie_id = $movieId
|""".stripMargin
.query[String]
.to[List]
val query = for {
maybeMovie <- findMovieByTitle()
directors <- maybeMovie match {
case Some((_, _, _, directorId)) => findDirectorById(directorId)
case None => List.empty[(String, String)].pure[ConnectionIO]
}
actors <- maybeMovie match {
case Some((movieId, _, _, _)) => findActorsByMovieId(movieId)
case None => List.empty[String].pure[ConnectionIO]
}
} yield {
maybeMovie.map { case (id, title, year, _) =>
val directorName = directors.head._1
val directorLastName = directors.head._2
Movie(id.toString, title, year, actors, s"$directorName $directorLastName")
}
}
query.transact(xa)
}
In the above code, we extracted information from the movies table, the directors table, and the actors table in sequence, and then we mapped the data to a Movie object. The ConnectionIO type is a monad. We can compose the queries in a sequence using the for-comprehension construct. Even though it’s not the main focus of this code, as we said, the three queries are executed in a single database transaction.
Now that we know all the pieces of a program that connects to a database using doobie, we can create a more complex example. For this purpose, we will use the tagless final approach. Again, the details of the tagless final approach are far beyond the scope of this tutorial. In summary, it’s a technique that allows us to manage dependencies between our components and abstract away the details of the concrete effect implementation.
In a tagless final approach, we first define an algebra as a trait, storing all the functions we implement for a type. If we take the Director type, we can define the following algebra:
trait Directors[F[_]] {
def findById(id: Int): F[Option[Director]]
def findAll: F[List[Director]]
def create(name: String, lastName: String): F[Int]
}
As we can see, we abstract away from the concrete effect implementation, replacing it with a type constructor F[_].
Then, we need an interpreter of the algebra, that is a concrete implementation of the functions defined in the algebra:
object Directors {
def make[F[_]: MonadCancelThrow](xa: Transactor[F]): Directors[F] = {
new Directors[F] {
import DirectorSQL._
def findById(id: Int): F[Option[Director]] =
sql"SELECT id, name, last_name FROM directors WHERE id = $id".query[Director].option.transact(xa)
def findAll: F[List[Director]] =
sql"SELECT id, name, last_name FROM directors".query[Director].to[List].transact(xa)
def create(name: String, lastName: String): F[Int] =
sql"INSERT INTO directors (name, last_name) VALUES ($name, $lastName)".update.withUniqueGeneratedKeys[Int]("id").transact(xa)
}
}
}
Following the approach suggested by Gabriel Volpe in his excellent book, Practical FP in Scala: A hands-on approach, we use a smart constructor to create an instance of the interpreter that we maintain private to the rest of the world. The implementation of every single function should not surprise us at this point. It’s just the same doobie code we’ve seen so far.
Since the Transactor is something our interpreter depends on, and it’s not related to any feature concerning the effect F[_], we can safely pass it as an explicit parameter of the smart constructor.
The Transactor type has a hard constraint on the effect F[_]. In fact, the effect should be an instance of at least a MonadCancelThrow, which is a monad that can effectively handle errors and is cancellable. The last property allows the monad to safely cancel executions and release / close resources.
We use context-bounds directly on F to define any constraint on the effect.
Finally, we can create a Directors instance using the smart constructor.
As we should remember, since we’ve defined the Director type through the use of many newtypes, we need to create a custom mapping using the Read and Write type classes. We can put the type classes definition inside a dedicated object:
private object DirectorSQL {
implicit val directorRead: Read[Director] =
Read[(Int, String, String)].map { case (id, name, lastname) =>
Director(DirectorId(id), DirectorName(name), DirectorLastName(lastname))
}
implicit val directorWrite: Write[Director] =
Write[(Int, String, String)].contramap { director =>
(director.id.id, director.name.name, director.lastName.lastName)
}
}
If we want to create a concrete instance of our interpreter, we need to create an instance of the Transactor resource. As we saw at the beginning of this article, we can use the Hikary extension for doobie:
val postgres: Resource[IO, HikariTransactor[IO]] = for {
ce <- ExecutionContexts.fixedThreadPool[IO](32)
xa <- HikariTransactor.newHikariTransactor[IO](
"org.postgresql.Driver",
"jdbc:postgresql:myimdb",
"postgres",
"example",
ce
)
} yield xa
Then, we can define the last part of the tagless final approach: a program using the interpreter. For example, let’s define a program that inserts the director of Jurassic Park into the database and then retrieve it. Notice how we’re creating the Directors[F] instance, by calling use on the postgres resource, thereby reusing the transactor on all queries.
val program: IO[Unit] = postgres.use { xa =>
val directors = Directors.make[IO](xa)
for {
id <- directors.create("Steven", "Spielberg")
spielberg <- directors.findById(id)
_ <- IO.println(s"The director of Jurassic Park is: $spielberg")
} yield ()
}
We can then put all the parts into a single IOApp and run the program:
object TaglessApp extends IOApp {
override def run(args: List[String]): IO[ExitCode] = {
val postgres: Resource[IO, HikariTransactor[IO]] = for {
ce <- ExecutionContexts.fixedThreadPool[IO](32)
xa <- HikariTransactor.newHikariTransactor[IO](
"org.postgresql.Driver",
"jdbc:postgresql:myimdb",
"docker",
"docker",
ce
)
} yield xa
val program: IO[Unit] = postgres.use { xa =>
val directors = Directors.make[IO](xa)
for {
id <- directors.create("Steven", "Spielberg")
spielberg <- directors.findById(id)
_ <- IO.println(s"The director of Jurassic Park is: $spielberg")
} yield ()
}
program.as(ExitCode.Success)
}
}
And that’s it!
Finally, we sum up what we’ve learned so far. We introduced doobie, a JDBC functional wrapper library built upon the Cats Effect library. After defining some domain models to work with, we learned how to create a Transactor object to execute instructions in the database. Then, we saw how to implement queries, both with and without input parameters, and map their results back to our domain models. So, we saw how to insert and update rows in a table, and then which are the available implementation when we need a join. Since doobie uses some type classes to map Scala type from and to schema types, we introduced them. Finally, we describe how to use doobie in a tagless final context with all the pieces in the right places.
Clearly, the article is not exhaustive, but it’s an excellent start understanding how to use doobie. We left out some advanced features, like testing, error handling, type-checking, and logging. If you want to deepen your knowledge concerning the doobie library, you can take a look at the official documentation.
Share on: